Web实战开发 — 百万级爬虫服务架构的总体设计与开发
随着互联网数据爆炸式增长,高效、稳定的爬虫服务成为企业数据获取的核心工具。尤其在百万级数据爬取场景下,系统需兼顾性能、可扩展性和容错能力。本文将详细探讨百万级爬虫服务架构的总体设计思路与软件开发实现。
一、总体架构设计
- 模块化分层结构
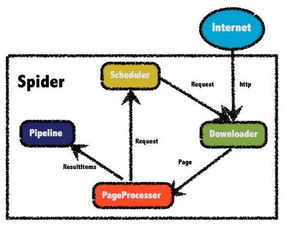
- 调度层:负责任务分配与优先级管理,采用分布式任务队列(如Redis、RabbitMQ)实现负载均衡。
- 爬取层:由多个爬虫节点组成,支持多线程/协程并发,通过IP代理池和User-Agent轮换规避反爬机制。
- 解析层:集成HTML解析库(如BeautifulSoup、lxml)与正则表达式,提取结构化数据。
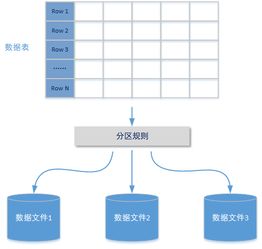
- 存储层:采用混合存储方案,关系型数据库(如MySQL)存储元数据,NoSQL(如MongoDB、Elasticsearch)存储非结构化数据,结合缓存(如Redis)提升读写效率。
- 监控层:实时收集节点状态、请求成功率等指标,通过Prometheus和Grafana实现可视化告警。
- 高可用与扩展性设计
- 采用微服务架构,各模块可独立部署和水平扩展。
- 引入容器化技术(如Docker + Kubernetes),实现快速弹性伸缩。
- 设计容错机制:任务重试、节点心跳检测、数据去重(布隆过滤器)等。
二、软件开发与实现
- 技术栈选择
- 开发语言:Python(Scrapy框架)或Go(高并发优势)。
- 消息队列:Redis或Kafka,保障任务有序分发。
- 代理与反反爬:集成第三方代理服务(如快代理),结合动态Cookie管理与请求频率控制。
- 核心开发流程
- 任务调度:通过Celery或自定义调度器实现分布式任务管理。
- 异步爬取:利用asyncio或Gevent提升I/O密集型任务效率。
- 数据清洗:在解析层嵌入数据验证规则,确保数据质量。
- 存储优化:采用分库分表策略,结合索引优化查询性能。
- 测试与部署
- 单元测试覆盖爬虫逻辑与解析规则。
- 压力测试模拟高并发场景,验证系统瓶颈。
- 使用CI/CD工具(如Jenkins、GitLab CI)自动化部署与更新。
三、挑战与优化方向
- 反爬策略应对:持续更新User-Agent池与IP代理,模拟人类行为。
- 资源控制:限制单节点带宽与请求频率,避免对目标站点造成压力。
- 法律与伦理:遵循robots.txt协议,确保数据采集合法性。
百万级爬虫服务架构需在性能、稳定性和可维护性间取得平衡。通过模块化设计、分布式技术与自动化运维,可构建高效可靠的数据采集系统,为业务决策提供强力支持。
如若转载,请注明出处:http://www.vipwujin.com/product/6.html
更新时间:2026-06-19 10:12:41